Docs
- Docs
- 1. Introduction
- 2. Basic Usage
- 3. Command Line Arguments
- 3.1 Using Options Files to Pass Arguments
- 3.2 Connecting to a Database Server
- 3.3 Selecting the Data to Replicate
- 3.4 Free-form Query Replications
- 3.5 Bandwidth Throttling
- 3.6 Data Type Transformations in Source Queries
- 4. Notes for specific connectors
- 5. Troubleshooting
- 6. Performance Tuning
- 7. Architecture
1. Introduction
ReplicaDB is a high-performance, portable, and cross-platform command-line tool for data replication between source and sink databases. It implements database engine-specific optimizations to achieve optimal performance for each supported database, whether used as a source or destination.
ReplicaDB follows the “Convention over Configuration” design principle, requiring users to provide only the minimum necessary parameters for replication while applying sensible defaults for all other settings.
2. Basic Usage
With ReplicaDB, you can replicate data between relational databases and non-relational databases. The input to the replication process is a database table or custom query. ReplicaDB will read the source table row-by-row and the output of this replication process is a table in the sink database containing a copy of the source data. The replication process is performed in parallel.
By default, ReplicaDB will truncate the sink table before populating it with data, unless --sink-disable-truncate false is indicated.
2.1 Replication Mode
ReplicaDB implements three replication modes: complete, complete-atomic and incremental.
Complete
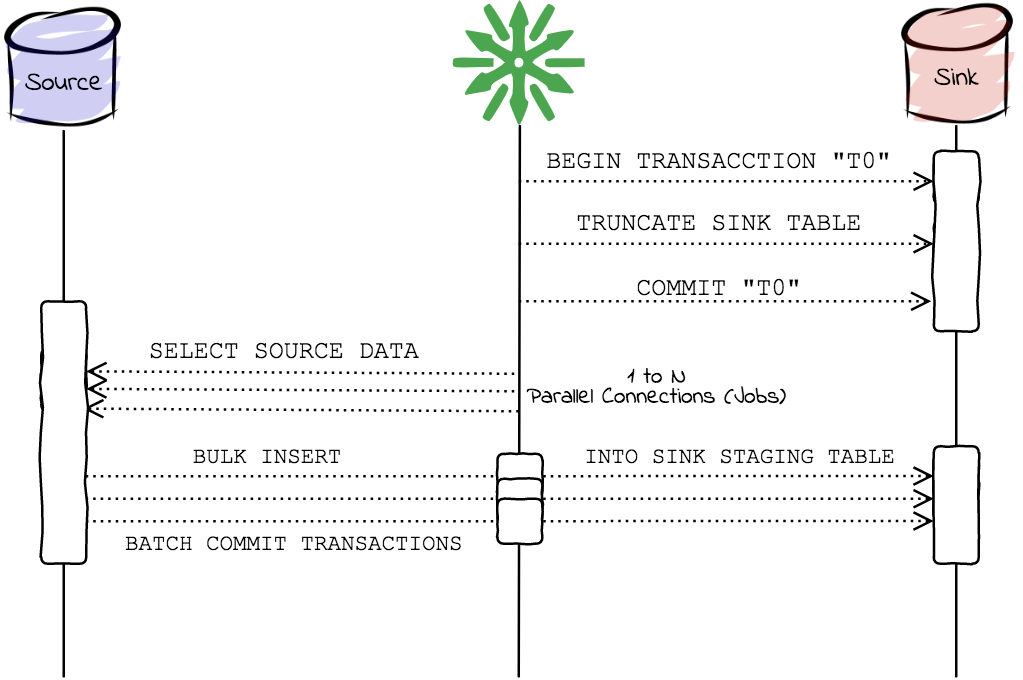
The complete mode makes a complete replica of the source table, of all its data, from source to sink. In complete mode, only INSERT is done in the sink table without worrying about the primary keys. ReplicaDB will perform the following actions on a complete replication:
- Truncate the sink table with the
TRUNCATE TABLEstatement. - Select and copy the data in parallel from the source table to the sink table.
So data is not available in the sink table during the replication process.
Complete Atomic
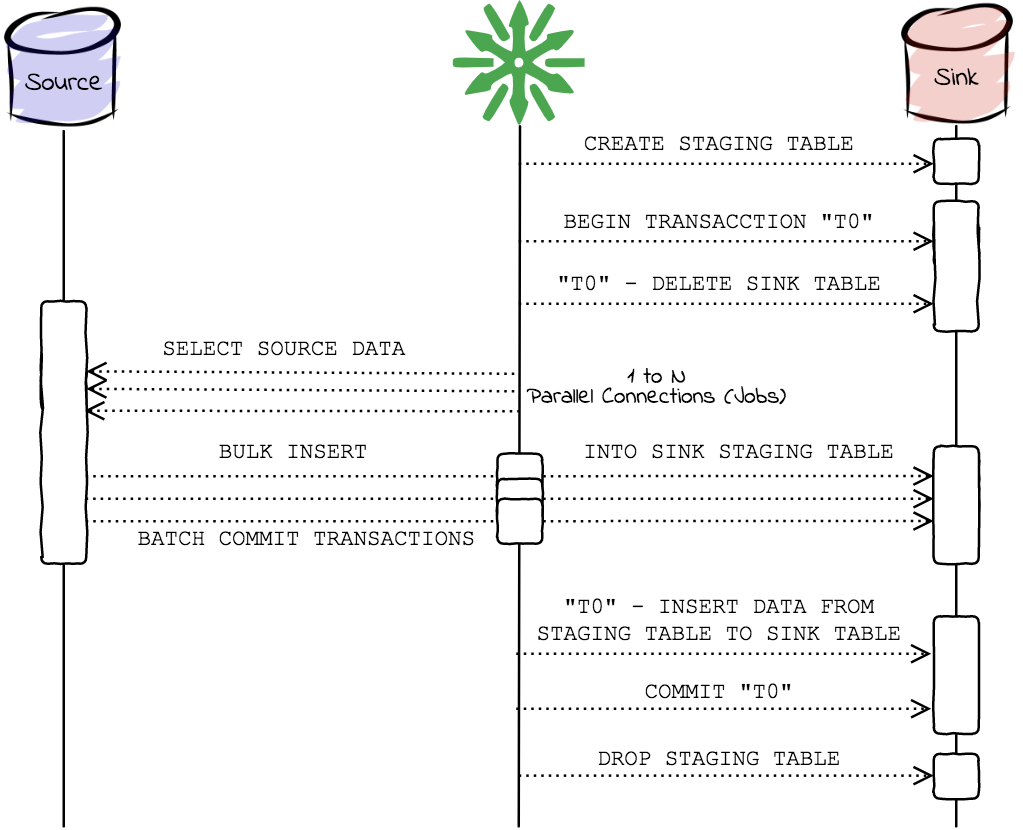
The complete-atomic mode performs a complete replication (DELETE and INSERT) in a single transaction, allowing the sink table to never be empty. ReplicaDB will perform the following actions on a complete-atomic replication:
- Automatically create the staging table in the sink database.
- Begin a new transaction, called
"T0", and delete the sink table with theDELETE FROMstatement. This operation is executed in a new thread, so ReplicaDB does not wait for the operation to finish. - Select and copy the data in parallel from the source table to the sink staging table.
- Wait until the
DELETEstatement of transaction"T0"is completed. - Using transaction
"T0"the data is moved (usingINSERT INTO ... SELECTstatement) from the sink staging table to the sink table. - Commit transaction
"T0". - Drop the sink staging table.
So data is available in the sink table during the replication process.
Incremental
The incremental mode performs an incremental replication of the data from the source table to the sink table. The incremental mode aims to replicate only the new data added in the source table to the sink table. This technique drastically reduces the amount of data that must be moved between both databases and becomes essential with large tables with billions of rows.
To do this, it is necessary to have a strategy for filtering the new data at the source. Usually, a date type column or a unique incremental ID is used. Therefore it will be necessary to use the source.where parameter to retrieve only the newly added rows in the source table since the last time the replica was executed.
Currently, you must store the last value of the column used to determine changes in the source table. In future versions, ReplicaDB will do this automatically.
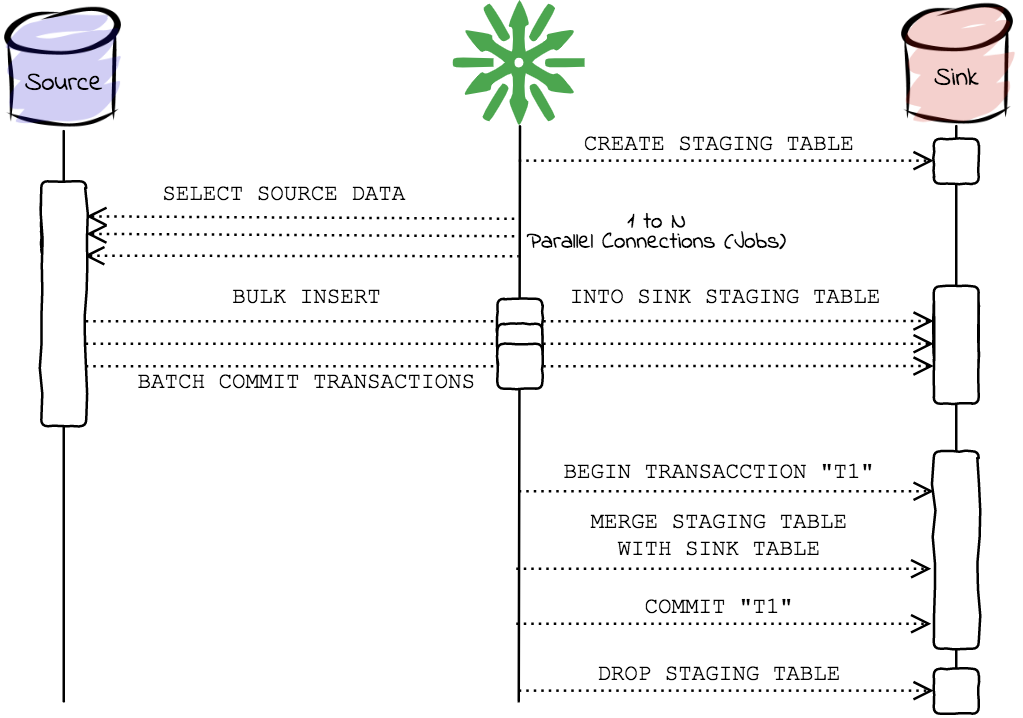
In the incremental mode, the INSERT or UPDATE or UPSERT technique is used in the sink table. ReplicaDB needs to create a staging table in the sink database, where data is copied in parallel. The last step of the replication is to merge the staging table with the sink table. ReplicaDB will perform the following actions in an incremental replication:
- Automatically create the staging table in the sink database.
- Truncate the staging table.
- Select and copy the data in parallel from the source table to the sink staging table.
- Gets the primary keys of the sink table
- Execute the
UPSERTsentence between the sink staging table and the sink table. This statement will depend on the Database Vendor, it can be for exampleINSERT ... ON CONFLICT ... DO UPDATEin PostgreSQL orMERGE INTO ...in Oracle. - Drop the sink staging table.
So data is available in the sink table during the replication process.
Deprecated Modes
CDC Mode (Removed)
The CDC (Change Data Capture) mode has been deprecated and removed from ReplicaDB. This mode previously required database triggers and maintained internal state, which increased complexity and maintenance overhead.
Migration Path: If you were using CDC mode, migrate to incremental mode with the --source-where parameter to filter changed records:
# Instead of CDC mode, use incremental with timestamp filtering
replicadb --mode=incremental \
--source-table=source_table \
--source-where="modified_date > TO_DATE('2026-01-01', 'YYYY-MM-DD')" \
--sink-table=sink_table
Store and manage the last synchronization timestamp in your orchestration layer (cron, Airflow, Jenkins) rather than relying on ReplicaDB to track state.
2.2 Controlling Parallelism
ReplicaDB replicates data in parallel from most database sources. You can specify the number of job tasks (parallel processes) to use to perform the replication by using the -j or --jobs argument. Each of these arguments takes an integer value which corresponds to the degree of parallelism to employ. By default, four tasks are used. Some databases may see improved performance by increasing this value to 8 or 16. Do not increase the degree of parallelism beyond what your database can reasonably support. Connecting 100 concurrent clients to your database may increase the load on the database server to a point where performance suffers as a result.
3. Command Line Arguments
ReplicaDB ships with a help tool. To display a list of all available options, type the following command:
$ replicadb --help
usage: replicadb [OPTIONS]
...
Table 1. Common arguments
| Argument | Description | Default |
|---|---|---|
--fetch-size <fetch-size> |
Number of entries to read from database at once. | 100 |
-h,--help |
Print this help screen | |
-j,--jobs <n> |
Use n jobs to replicate in parallel. | 4 |
--mode <mode> |
Specifies the replication mode. The allowed values are complete, complete-atomic or incremental |
complete |
--options-file <file-path> |
Options file path location | |
--quoted-identifiers |
Should all database identifiers be quoted. | false |
--sink-columns <col,col,col...> |
Sink database table columns to be populated | --source-columns |
--sink-connect <jdbc-uri> |
Sink database JDBC connect string | required |
--sink-disable-escape |
Escape strings before populating to the table of the sink database. | false |
--sink-disable-truncate |
Disable the truncation of the sink database table before populate. | false |
--sink-password <password> |
Sink database authentication password | |
--sink-staging-schema <schema-name> |
Schema name on the sink database, with right permissions for creating staging tables. | PUBLIC |
--sink-staging-table <table-name> |
Qualified name of the sink staging table. The table must exist in the sink database. | |
--sink-staging-table-alias <staging-table-name-alias> |
Alias name for the sink staging table. | |
--sink-table <table-name> |
Sink database table to populate | --source-table |
--sink-user <username> |
Sink database authentication username | |
--source-columns <col,col,col...> |
Source database table columns to be extracted | * |
--source-connect <jdbc-uri> |
Source database JDBC connect string | required |
--source-password <password> |
Source database authentication password | |
--source-query <statement> |
SQL statement to be executed in the source database | |
--source-table <table-name> |
Source database table to read | |
--source-user <username> |
Source database authentication username | |
--source-where <where clause> |
Source database WHERE clause to use during extraction | |
--bandwidth-throttling <KB/s> |
Limits replication bandwidth to specified kilobytes per second. 0 means unlimited. | 0 |
-v,--verbose |
Print more information while working | |
--version |
Show implementation version and exit |
3.1 Using Options Files to Pass Arguments
When using ReplicaDB, the command line options that do not change from invocation to invocation can be put in an options file for convenience. An options file is a Java properties text file where each line identifies an option. Option files allow specifying a single option on multiple lines by using the back-slash character at the end of intermediate lines. Also supported are comments within option files that begin with the hash character. Comments must be specified on a new line and may not be mixed with option text. All comments and empty lines are ignored when option files are expanded.
Option files can be specified anywhere on the command line. Command line arguments override those in the options file. To specify an options file, simply create an options file in a convenient location and pass it to the command line via --options-file argument.
For example, the following ReplicaDB invocation for replicate a full table into PostgreSQL can be specified alternatively as shown below:
$ replicadb --source-connect jdbc:postgresql://localhost/osalvador \
--source-table TEST \
--sink-connect jdbc:postgresql://remotehost/testdb \
--sink-user=testusr \
--sink-table TEST \
--mode complete
$ replicadb --options-file /users/osalvador/work/import.txt -j 4
where the options file /users/osalvador/work/import.txt contains the following:
source.connect=jdbc:postgresql://localhost/osalvador
source.table=TEST
sink.connect=jdbc:postgresql://remotehost/testdb
sink.user=testusr
sink.table=TEST
mode=complete
Using environment variables in options file
If you are familiar with Ant or Maven, you have most certainly already encountered the variables (like ${token}) that are automatically expanded when the configuration file is loaded. ReplicaDB supports this feature as well, here is an example:
source.connect=jdbc:postgresql://${PGHOST}/${PGDATABASE}
source.user=${PGUSER}
source.password=${PGPASSWORD}
source.table=TEST
Variables are interpolated from system properties. ReplicaDB will search for a system property with the given name and replace the variable by its value. This is a very easy means for accessing the values of system properties in the options configuration file.
Note that if a variable cannot be resolved, e.g. because the name is invalid or an unknown prefix is used, it won’t be replaced, but is returned as-is including the dollar sign and the curly braces.
3.2 Connecting to a Database Server
ReplicaDB is designed to replicate tables between databases. To do so, you must specify a connect string that describes how to connect to the database. The connect string is similar to a URL and is communicated to ReplicaDB with the --source-connect or --sink-connect arguments. This describes the server and database to connect to; it may also specify the port. For example:
$ replicadb --source-connect jdbc:mysql://database.example.com/employees
This string will connect to a MySQL database named employees on the host database.example.com.
You might need to authenticate against the database before you can access it. You can use the --source-username or --sink-username to supply a username to the database.
ReplicaDB provides a couple of different ways to supply a password, secure and non-secure, to the database which is detailed below.
Specifying extra JDBC parameters
When connecting to a database using JDBC, you can optionally specify extra JDBC parameters only via the options file. The contents of these properties are parsed as standard Java properties and passed into the driver while creating a connection.
You can specify these parameters for both the source and sink databases. ReplicaDB will retrieve all the parameters that start with source.connect.parameter. or sink.connect.parameter. followed by the name of the specific parameter of the database engine.
Examples:
# Source JDBC connection parameters
# source.connect.parameter.[parameter_name]=parameter_value
# Example for Oracle
source.connect.parameter.oracle.net.tns_admin=${TNS_ADMIN}
source.connect.parameter.oracle.net.networkCompression=on
source.connect.parameter.defaultRowPrefetch=5000
# Sink JDBC connection parameters
# sink.connect.parameter.[parameter_name]=parameter_value
# Example for PostgreSQL
sink.connect.parameter.ApplicationName=ReplicaDB
sink.connect.parameter.reWriteBatchedInserts=true
Secure way of supplying a password to the database
To supply a password securely, the options file must be used using the --options-file argument. For example:
$ replicadb --source-connect jdbc:mysql://database.example.com/employees \
--source-user boss --options-file ./conf/employee.conf
where the options file ./conf/employee.conf contains the following:
source.password=myEmployeePassword
Unsecure way of supplying password to the database
$ replicadb --source-connect jdbc:mysql://database.example.com/employees \
--source-user boss --source-password myEmployeePassword
3.3 Selecting the Data to Replicate
ReplicaDB typically replicates data in a table-centric fashion. Use the --source-table argument to select the table to replicate. For example, --source-table employees. This argument can also identify a VIEW or other table-like entity in a database.
By default, all columns within a table are selected for replication. You can select a subset of columns and control their ordering by using the --source-columns argument. This should include a comma-delimited list of columns to replicate. For example: --source-columns "name,employee_id,jobtitle".
You can control which rows are replicated by adding a SQL WHERE clause to the statement. By default, ReplicaDB generates statements of the form SELECT <column list> FROM <table name>. You can append a WHERE clause to this with the --source-where argument. For example: --source-where "id > 400". Only rows where the id column has a value greater than 400 will be replicated.
3.4 Free-form Query Replications
ReplicaDB can also replicate the result set of an arbitrary SQL query. Instead of using the --source-table, --source-columns and --source-where arguments, you can specify a SQL statement with the --source-query argument.
For example:
$ replicadb --source-query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id)'
3.5 Bandwidth Throttling
ReplicaDB supports bandwidth throttling to prevent network saturation during large replication jobs. Use the --bandwidth-throttling parameter to specify a maximum transfer rate in kilobytes per second.
Supported Databases:
- Oracle (Source/Sink)
- PostgreSQL (Source/Sink)
- MySQL/MariaDB (Source/Sink)
- DB2 (Source/Sink)
- MongoDB (Source/Sink)
- SQLite (Source/Sink)
- Kafka (Sink only)
- Standard JDBC-compliant databases (Source/Sink)
Not Supported:
- SQL Server
- CSV/Local Files
- Amazon S3
Example:
$ replicadb --mode=complete \
--source-connect=jdbc:oracle:thin:@host:port:sid \
--source-user=user \
--source-password=pass \
--source-table=large_table \
--sink-connect=jdbc:postgresql://host/db \
--sink-user=user \
--sink-password=pass \
--sink-table=large_table \
--bandwidth-throttling=10240 # Limit to 10 MB/s
Or using an options file:
mode=complete
jobs=4
bandwidth.throttling=10240
source.connect=jdbc:oracle:thin:@host:port:sid
source.user=user
source.password=pass
source.table=large_table
sink.connect=jdbc:postgresql://host/db
sink.user=user
sink.password=pass
sink.table=large_table
Note: Bandwidth throttling is applied per job. If you use 4 parallel jobs with a 10 MB/s limit, the total bandwidth could reach up to 40 MB/s.
3.6 Data Type Transformations in Source Queries
ReplicaDB is designed as a data transport tool, not a data transformation tool. It replicates data faithfully from source to sink without applying transformations or ETL logic. However, different database systems have incompatible data types that may require transformation at the database level before replication.
Design Philosophy:
- ReplicaDB focuses on efficient bulk data transfer
- Data transformations should be performed by the source database, not by ReplicaDB
- Use
--source-queryto transform data types at the source before replication
When to Use Source Query Transformations:
- Incompatible data types between source and sink databases
- JSON/JSONB columns that require string conversion
- LOB types (CLOB/BLOB) that need casting
- Numeric precision exceeding sink database limits
- Custom data formatting requirements
3.6.1 JSON Type Transformations
JSON types are handled differently across database systems. When replicating JSON columns between heterogeneous databases, you may need to convert them to text at the source.
MySQL/MariaDB to SQL Server
Problem: MySQL stores JSON as strings with quotes, but SQL Server validates JSON format strictly and rejects improperly formatted values.
Solution: Use JSON_UNQUOTE() or CAST() to convert JSON to plain text:
# Using JSON_UNQUOTE (recommended for JSON columns)
$ replicadb --mode=complete \
--source-connect=jdbc:mysql://mysql-host:3306/mydb \
--source-user=root \
--source-password=pass \
--source-query='SELECT id, name, JSON_UNQUOTE(json_data) as json_data FROM source_table' \
--sink-connect=jdbc:sqlserver://sqlserver-host:1433;databaseName=mydb \
--sink-user=sa \
--sink-password=pass \
--sink-table=target_table
# Using CAST (converts JSON to VARCHAR)
$ replicadb --mode=complete \
--source-query='SELECT id, CAST(json_array AS CHAR(5000)) as json_array, CAST(json_object AS CHAR(5000)) as json_object FROM t_source'
Options file format:
mode=complete
jobs=4
source.connect=jdbc:mysql://mysql-host:3306/mydb
source.user=root
source.password=pass
source.query=SELECT id, name, JSON_UNQUOTE(json_data) as json_data, JSON_UNQUOTE(json_array) as json_array FROM source_table
sink.connect=jdbc:sqlserver://sqlserver-host:1433;databaseName=mydb
sink.user=sa
sink.password=pass
sink.table=target_table
PostgreSQL to MySQL/MariaDB
Problem: PostgreSQL JSONB type may not map correctly to MySQL JSON type.
Solution: Cast JSONB to TEXT at the source:
$ replicadb --mode=complete \
--source-connect=jdbc:postgresql://pg-host:5432/mydb \
--source-user=postgres \
--source-password=pass \
--source-query='SELECT id, name, json_column::TEXT as json_column, jsonb_column::TEXT as jsonb_column FROM source_table' \
--sink-connect=jdbc:mysql://mysql-host:3306/mydb \
--sink-table=target_table
Oracle to PostgreSQL
Problem: Oracle doesn’t have native JSON type (pre-21c), uses CLOB or VARCHAR2 for JSON data.
Solution: Ensure JSON is stored as TEXT/VARCHAR:
$ replicadb --mode=complete \
--source-connect=jdbc:oracle:thin:@oracle-host:1521:ORCL \
--source-user=system \
--source-password=pass \
--source-query='SELECT id, name, TO_CHAR(json_clob) as json_data FROM source_table' \
--sink-connect=jdbc:postgresql://pg-host:5432/mydb \
--sink-table=target_table
MongoDB to Relational Databases
Problem: MongoDB stores native BSON/JSON that needs conversion for relational databases.
Solution: Use aggregation pipeline to convert to string representation:
source.connect=mongodb://mongo-host:27017/mydb
source.table=mycollection
source.query=[{$project: {_id:1, name:1, json_field: {$toString: "$json_field"}}}]
sink.connect=jdbc:postgresql://pg-host:5432/mydb
sink.table=target_table
3.6.2 LOB Type Transformations
CLOB to VARCHAR
When replicating CLOB columns to databases with VARCHAR limits, convert at source:
# Oracle CLOB to PostgreSQL TEXT
$ replicadb --source-query='SELECT id, name, DBMS_LOB.SUBSTR(clob_column, 32767, 1) as clob_column FROM source_table'
# Oracle CLOB to MySQL VARCHAR
$ replicadb --source-query='SELECT id, TO_CHAR(clob_column) as clob_column FROM source_table WHERE DBMS_LOB.GETLENGTH(clob_column) <= 65535'
BLOB to Binary/VARBINARY
Convert BLOB to hexadecimal string for text-based sinks:
# Oracle BLOB to hex string
$ replicadb --source-query='SELECT id, RAWTOHEX(blob_column) as blob_hex FROM source_table'
# PostgreSQL BYTEA to hex
$ replicadb --source-query='SELECT id, encode(bytea_column, '\''hex'\'') as bytea_hex FROM source_table'
3.6.3 Numeric Precision Transformations
Different databases have varying numeric precision limits. Transform at source to avoid overflow:
# Oracle NUMBER(38,10) to SQL Server DECIMAL(38,10) - exceeds SQL Server max precision
$ replicadb --source-query='SELECT id, ROUND(amount, 8) as amount FROM source_table'
# MySQL DECIMAL(65,30) to PostgreSQL NUMERIC(38,10)
$ replicadb --source-query='SELECT id, CAST(large_decimal AS DECIMAL(38,10)) as large_decimal FROM source_table'
3.6.4 Date/Time Format Transformations
Standardize date formats for cross-database compatibility:
# Oracle DATE to ISO format string
$ replicadb --source-query='SELECT id, TO_CHAR(date_column, '\''YYYY-MM-DD HH24:MI:SS'\'') as date_column FROM source_table'
# MySQL DATETIME to Unix timestamp
$ replicadb --source-query='SELECT id, UNIX_TIMESTAMP(datetime_column) as datetime_unix FROM source_table'
# PostgreSQL TIMESTAMP to ISO string
$ replicadb --source-query='SELECT id, TO_CHAR(timestamp_column, '\''YYYY-MM-DD"T"HH24:MI:SS"Z"'\'') as timestamp_iso FROM source_table'
3.6.5 Custom Transformations
Apply business logic at the source database:
# Concatenate columns
$ replicadb --source-query='SELECT id, CONCAT(first_name, '\'' '\'', last_name) as full_name FROM source_table'
# Conditional transformations
$ replicadb --source-query='SELECT id, CASE WHEN status=1 THEN '\''active'\'' ELSE '\''inactive'\'' END as status_text FROM source_table'
# NULL handling
$ replicadb --source-query='SELECT id, COALESCE(nullable_column, '\''DEFAULT'\'') as nullable_column FROM source_table'
3.6.6 Important Limitations
Parallel Processing Constraints:
Some databases don’t support parallel processing with custom queries:
- Oracle: Custom queries (
--source-query) disable parallel processing. Use--source-table,--source-columns, and--source-whereinstead for parallel execution. - SQL Server: Same limitation as Oracle.
For maximum performance with these databases, consider:
- Create a database view with transformations
- Use the view as
--source-tablefor parallel processing - Or accept single-threaded processing with
--source-queryand-j=1
Example using a view:
-- Create view in source database
CREATE VIEW v_transformed_data AS
SELECT id, name, JSON_UNQUOTE(json_data) as json_data
FROM source_table;
# Use view for parallel replication
$ replicadb --mode=complete -j=4 \
--source-table=v_transformed_data \
--sink-table=target_table
3.6.7 Best Practices
- Test transformations in the source database first before using in ReplicaDB
- Consider performance impact of complex transformations on source database
- Use database views when same transformation is needed repeatedly
- Document transformations in your data pipeline documentation
- Validate data types match between source query output and sink table
- Use appropriate string lengths when casting to VARCHAR/CHAR
- Handle NULL values explicitly in transformations
- Monitor source database load when applying transformations
3.6.8 Troubleshooting
Error: “JSON text is not properly formatted”
- Cause: JSON column contains quoted strings that SQL Server validates as invalid JSON
- Solution: Use
JSON_UNQUOTE()orCAST()in source query
Error: “Numeric overflow” or “Value out of range”
- Cause: Source numeric precision exceeds sink database limits
- Solution: Use
ROUND()orCAST()to reduce precision in source query
Error: “String data would be truncated”
- Cause: Source string/LOB length exceeds sink column size
- Solution: Use
SUBSTR()orLEFT()functions to truncate in source query
Performance degradation with source-query
- Cause: Oracle/SQL Server disable parallel processing with custom queries
- Solution: Create a database view and use
--source-tableinstead
4. Notes for specific connectors
- 4.1 CSV files Connector
- 4.2 Oracle Connector
- 4.3 PostgreSQL Connector
- 4.4 Denodo Connector
- 4.10 DB2 Connector
4.1 CSV files Connector
The CSV File Connector uses the Apache Commons CSV library to read and write the CSV files.
To define a CSV file, set the source-connect or sink-connect parameter to file:/....
############################# Source Options #############################
# Windows Paths
source.connect=file:/C:/Users/osalvador/Downloads/file.csv
source.connect=file://C:\\Users\\osalvador\\Downloads\\file.csv
# Unix Paths
source.connect=file:///Users/osalvador/Downloads/file.csv
source.columns=id, name, born
source.connect.parameter.columns.types=integer, varchar, date
############################# Sink Options #############################
# Windows Paths
sink.connect=file:/C:/Users/osalvador/Downloads/file.csv
sink.connect=file://C:\\Users\\osalvador\\Downloads\\file.csv
# Unix Paths
sink.connect=file:///Users/osalvador/Downloads/file.csv
By default the format of the CSV File is the DEFAULT predefined format:
delimiter=,
quote="
recordSeparator=\r\n
ignoreEmptyLines=true
Note: The format is taken as the base format, you can modify any of its attributes by setting the rest parameters.
4.1.1 CSV File as Source
When defining a CSV file as a Source, you should note that the columns.types parameter is required.
This parameter defines the format of the columns in the CSV file. This should include a comma-delimited list of columns data types and the exact number of columns in the CSV file.
For example, you set the parameter with source.connect.parameter.columns.types=integer,varchar,date for a CSV File with 3 columns.
4.1.2 Supported Data Types for CSV file as Source
You can read all columns in the CSV file as VARCHAR and ReplicaDB will store them in a String. But, if you want to make a standard parsing of your data, you should define the correct data type of your column.
CSV supported data Types Mapped to Java Types
| CSV Data Type | Java Type | Parser |
|---|---|---|
VARCHAR |
String |
|
CHAR |
String |
|
LONGVARCHAR |
String |
|
INTEGER |
int |
Integer.parseInt() |
BIGINT |
long |
Long.parseLong() |
TINYINT |
byte |
Byte.parseByte() |
SMALLINT |
short |
Short.parseShort() |
NUMERIC |
java.math.BigDecimal |
new BigDecimal() |
DECIMAL |
java.math.BigDecimal |
new BigDecimal() |
DOUBLE |
double |
Double.parseDouble() |
FLOAT |
float |
Float.parseFloat() |
DATE |
java.sql.Date |
Date.valueOf() |
TIMESTAMP |
java.sql.Timestamp |
Timestamp.valueOf() |
TIME |
java.sql.Time |
Time.valueOf() |
BOOLEAN |
boolean |
Custom Boolean Parser |
Custom Boolean Parser
The boolean returned represents the value true if the string argument is not null and is equal, ignoring case, to the string true, yes, on, 1, t, y.
4.1.3 Predefined CSV Formats
Thanks to Apache Commons CSV you can read or write CSV files in several predefined formats or customize yours with the available parameters.
You can use these predefined formats to read or write CSV files. To define a CSV format, set the format extra parameter to any of these available formats: DEFAULT, EXCEL, INFORMIX_UNLOAD, INFORMIX_UNLOAD_CSV, MONGO_CSV, MONGO_TSV, MYSQL, ORACLE, POSTGRESQL_CSV, POSTGRESQL_TEXT, RFC4180, TDF.
Example
source.connect.parameter.format=RFC4180
DEFAULT
Standard Comma Separated Value format, as for RFC4180 but allowing empty lines.
Settings are:
delimiter=,
quote="
recordSeparator=\r\n
ignoreEmptyLines=true
EXCEL
The Microsoft Excel CSV format.
Excel file format (using a comma as the value delimiter). Note that the actual value delimiter used by Excel is locale dependent, it might be necessary to customize this format to accommodate to your regional settings.
Settings are:
delimiter=,
quote="
recordSeparator=\r\n
ignoreEmptyLines=false
INFORMIX_UNLOAD
Informix UNLOAD format used by the UNLOAD TO file_name operation.
This is a comma-delimited format with a LF character as the line separator. Values are not quoted and special characters are escaped with \.
Settings are:
delimiter=,
escape=\\
quote="
recordSeparator=\n
INFORMIX_UNLOAD_CSV
Informix CSV UNLOAD format used by the UNLOAD TO file_name operation (escaping is disabled.)
This is a comma-delimited format with a LF character as the line separator. Values are not quoted and special characters are escaped with \.
Settings are:
delimiter=,
quote="
recordSeparator=\n
MONGO_CSV
MongoDB CSV format used by the mongoexport operation.
This is a comma-delimited format. Values are double quoted only if needed and special characters are escaped with ". A header line with field names is expected.
Settings are:
delimiter=,
escape="
quote="
quoteMode=ALL_NON_NULL
MONGODB_TSV
Default MongoDB TSV format used by the mongoexport operation.
This is a tab-delimited format. Values are double quoted only if needed and special characters are escaped with ". A header line with field names is expected.
Settings are:
delimiter=\t
escape="
quote="
quoteMode=ALL_NON_NULL
MYSQL
Default MySQL format used by the SELECT INTO OUTFILE and LOAD DATA INFILE operations.
This is a tab-delimited format with a LF character as the line separator. Values are not quoted and special characters are escaped with \. The default NULL string is \N.
Settings are:
delimiter=\t
escape=\\
ignoreEmptyLines=false
quote=null
recordSeparator=\n
nullString=\N
quoteMode=ALL_NON_NULL
ORACLE
Default Oracle format used by the SQL*Loader utility.
This is a comma-delimited format with the system line separator character as the record separator. Values are double quoted when needed and special characters are escaped with ". The default NULL string is "". Values are trimmed.
Settings are:
delimiter=,
escape=\\
ignoreEmptyLines=false
quote="
nullString=\N
trim=true
quoteMode=MINIMAL
POSTGRESQL_CSV
Default PostgreSQL CSV format used by the COPY operation.
This is a comma-delimited format with a LF character as the line separator. Values are double quoted and special characters are escaped with ". The default NULL string is "".
Settings are:
delimiter=,
escape="
ignoreEmptyLines=false
quote="
recordSeparator=\n
nullString=""
quoteMode=ALL_NON_NULL
POSTGRESQL_TEXT
Default PostgreSQL text format used by the COPY operation.
This is a tab-delimited format with a LF character as the line separator. Values are double quoted and special characters are escaped with ". The default NULL string is \\N.
Settings are:
delimiter=\t
escape=\\
ignoreEmptyLines=false
quote="
recordSeparator=\n
nullString=\\N
quoteMode=ALL_NON_NULL
RFC4180
The RFC-4180 format defined by RFC-4180.
Settings are:
delimiter=,
quote="
recordSeparator=\r\n
ignoreEmptyLines=false
TDF
A tab delimited format.
Settings are:
delimiter=\t
quote="
recordSeparator=\r\n
ignoreSurroundingSpaces=true
4.1.4 Predefined Quote Modes
You can set a predefined quote mode policy when writing a CSV File as a sink. To define a quote mode, set the format.quoteMode extra parameter to any of these available formats: ALL, ALL_NON_NULL, MINIMAL, NON_NUMERIC, NONE.
| Name | Description |
|---|---|
ALL |
Quotes all fields. |
ALL_NON_NULL |
Quotes all non-null fields. |
MINIMAL |
Quotes fields which contain special characters such as the field delimiter, quote character, or any of the characters in the line separator string. |
NON_NUMERIC |
Quotes all non-numeric fields. |
NONE |
Never quote fields. |
4.1.5 Extra parameters
The CSV connector supports the following extra parameters that can only be defined as extra connection parameters in the options-file:
| Parameter | Description | Default |
|---|---|---|
columns.types |
Sets the columns data types. This parameter is required for Source CSV Files | |
format |
Sets the base predefined CSV format | DEFAULT |
format.delimiter |
Sets the field delimiter character | , |
format.escape |
Sets the escape character | |
format.quote |
Sets the quoteChar character | " |
format.recordSeparator |
Sets the end-of-line character. This parameter only take effect on Snik CSV Files | |
format.firstRecordAsHeader |
Sets whether the first line of the file should be the header, with the names of the fields | false |
format.ignoreEmptyLines |
Sets whether empty lines between records are ignored on Source CSV Files | true |
format.nullString |
Sets the nullString character | |
format.ignoreSurroundingSpaces |
Sets whether spaces around values are ignored on Source CSV files | |
format.quoteMode |
Sets the quote policy on Sink CSV files | |
format.trim |
Sets whether to trim leading and trailing blanks |
Complete Example for CSV File as Source and Sink
############################# ReplicadB Basics #############################
mode=complete
jobs=1
############################# Source Options #############################
source.connect=file:///Users/osalvador/Downloads/fileSource.txt
source.connect.parameter.columns.types=integer, integer, varchar, time, float, boolean
source.connect.parameter.format=DEFAULT
source.connect.parameter.format.delimiter=|
source.connect.parameter.format.escape=\\
source.connect.parameter.format.quote="
source.connect.parameter.format.recordSeparator=\n
source.connect.parameter.format.firstRecordAsHeader=true
source.connect.parameter.format.ignoreEmptyLines=true
source.connect.parameter.format.nullString=
source.connect.parameter.format.ignoreSurroundingSpaces=true
source.connect.parameter.format.trim=true
############################# Sink Options #############################
sink.connect=file:///Users/osalvador/Downloads/fileSink.csv
sink.connect.parameter.format=RFC4180
sink.connect.parameter.format.delimiter=,
sink.connect.parameter.format.escape=\\
sink.connect.parameter.format.quote="
sink.connect.parameter.format.recordSeparator=\n
sink.connect.parameter.format.nullString=
sink.connect.parameter.format.quoteMode=non_numeric
############################# Other #############################
verbose=true
4.1.6 Replication Mode
Unlike in a database, the replication mode for a CSV file as sink has a slight difference:
- complete: Create a new file. If the file exists it is overwritten with the new data.
- incremental: Add the new data to the existing file. If the file does not exist, it creates it.
Unsupported Modes:
- complete-atomic: Not supported for CSV files. The atomic transaction semantics cannot be applied to file-based sinks.
The
firstRecordAsHeader=trueparameter is not supported onincrementalmode.
Example
############################# ReplicadB Basics #############################
mode=complete
jobs=4
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@host:port:sid
source.user=orauser
source.password=orapassword
source.table=schema.table_name
############################# Sink Options #############################
sink.connect=file:///Users/osalvador/Downloads/file.csv
4.1.7 ORC File Format Support
ReplicaDB supports reading from and writing to Apache ORC (Optimized Row Columnar) files, which provide efficient columnar storage with built-in compression and encoding optimizations.
Using ORC Files as Source
To read from an ORC file, specify the file path with file:// protocol and set the source file format:
############################# Source Options #############################
source.connect=file:///path/to/data.orc
source.file-format=orc
Command-line example:
replicadb --mode=complete \
--source-connect="file:///Users/data/input.orc" \
--source-file-format=orc \
--sink-connect="jdbc:postgresql://localhost/mydb" \
--sink-table=target_table
Using ORC Files as Sink
To write data to an ORC file:
############################# Sink Options #############################
sink.connect=file:///path/to/output.orc
sink.file-format=orc
Command-line example:
replicadb --mode=complete \
--source-connect="jdbc:oracle:thin:@host:1521:sid" \
--source-user=myuser \
--source-password=mypass \
--source-table=source_table \
--sink-connect="file:///Users/data/output.orc" \
--sink-file-format=orc
ORC File Format Characteristics
- Columnar Storage: ORC stores data by columns rather than rows, enabling efficient compression and query performance
- Built-in Compression: Supports ZLIB, SNAPPY, and LZO compression algorithms
- Type System: Rich type system including complex types (structs, maps, arrays)
- Predicate Pushdown: Metadata allows skipping irrelevant data blocks during reads
- ACID Support: Designed for Hadoop ecosystem with transactional semantics
Supported Data Types
ORC files support all standard SQL data types:
- Numeric: TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, DECIMAL
- String: STRING, VARCHAR, CHAR
- Date/Time: DATE, TIMESTAMP
- Binary: BINARY
- Boolean: BOOLEAN
- Complex: STRUCT, MAP, ARRAY, UNION
Replication Mode Restrictions
- complete: ✅ Supported - Creates new ORC file, overwrites if exists
- incremental: ✅ Supported - Appends data to existing ORC file
- complete-atomic: ❌ Not supported - Atomic transactions not applicable to file-based sinks
Limitations and Notes
- Parallel Processing: When using ORC files as source,
--jobsmust be set to1(single-threaded reads) - Schema Evolution: Schema must match between source and existing sink ORC file when using incremental mode
- File Format: Only CSV and ORC file formats are fully implemented.
- Compression: Default compression settings are used; custom compression parameters are not currently configurable via command-line
Performance Considerations
- Reading: ORC’s columnar format and compression make it faster than CSV for analytical queries
- Writing: Initial write may be slower than CSV due to compression overhead, but file sizes are typically 60-70% smaller
- Memory: ORC operations may require more memory than CSV due to columnar buffering
Example: Oracle to ORC to PostgreSQL Pipeline
# Step 1: Extract from Oracle to ORC file
replicadb --mode=complete \
--source-connect="jdbc:oracle:thin:@prod:1521:orcl" \
--source-user=extract_user \
--source-table=sales_data \
--sink-connect="file:///data/staging/sales_data.orc" \
--sink-file-format=orc
# Step 2: Load from ORC file to PostgreSQL
replicadb --mode=complete \
--source-connect="file:///data/staging/sales_data.orc" \
--source-file-format=orc \
--sink-connect="jdbc:postgresql://warehouse:5432/analytics" \
--sink-user=load_user \
--sink-table=sales_data
4.2 Oracle Connector
To connect to an Oracle database, either as a source or sink, we must specify a Database URL string. In the Oracle documentation you can review all available options:Oracle Database URLs and Database Specifiers
4.2.1 Connection String Formats
Oracle supports different connection string formats depending on your database configuration:
SID Format (Legacy)
Use this format for traditional Oracle databases with SID identifiers:
jdbc:oracle:thin:@${DBHOST}:${DBPORT}:${ORASID}
Service Name Format (Recommended for PDB)
Use this format for Oracle 12c+ Pluggable Databases (PDB) or when using service names. This is the required format for Oracle 19c PDB connections:
jdbc:oracle:thin:@//${DBHOST}:${DBPORT}/${SERVICE_NAME}
TNSNames Alias Format
To specify a connection using a TNSNames alias, you must set the oracle.net.tns_admin property:
jdbc:oracle:thin:@MY_DATABASE_ALIAS
Examples
Example using SID format (legacy databases):
############################# ReplicadB Basics #############################
mode=complete
jobs=4
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@${ORAHOST}:${ORAPORT}:${ORASID}
source.user=${ORAUSER}
source.password=${ORAPASS}
source.table=schema.table_name
############################# Sink Options #############################
...
Example using Service Name format (Oracle 19c PDB):
############################# ReplicadB Basics #############################
mode=complete
jobs=4
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@//${ORAHOST}:${ORAPORT}/${SERVICE_NAME}
source.user=${ORAUSER}
source.password=${ORAPASS}
source.table=schema.table_name
############################# Sink Options #############################
...
Example using TNSNames alias:
############################# ReplicadB Basics #############################
mode=complete
jobs=4
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@MY_DATABASE_SID
source.user=orauser
source.password=orapassword
source.table=schema.table_name
source.connect.parameter.oracle.net.tns_admin=${TNS_ADMIN}
source.connect.parameter.oracle.net.networkCompression=on
############################# Sink Options #############################
...
4.2.2 Oracle Flashback Query for Large Tables
ReplicaDB automatically uses Oracle Flashback Query to prevent ORA-01555 (“snapshot too old”) errors when replicating large tables. This feature captures a System Change Number (SCN) at the start of the job and uses it for all queries, providing read consistency without holding long-running database transactions.
How it works:
- At job start, ReplicaDB captures the current SCN from Oracle
- All SELECT queries use the
AS OF SCN <captured_scn>clause - Each parallel thread sees a consistent snapshot without locking undo segments
- No open transactions are held, eliminating ORA-01555 errors
Requirements:
- Oracle 9i or later (Flashback Query introduced in Oracle 9i)
- User must have SELECT access to
V$DATABASEsystem view - SCN must be within Oracle’s
UNDO_RETENTIONwindow
Troubleshooting:
If you see a warning in the logs: Could not capture Oracle SCN (V$DATABASE not accessible)
- Cause: User lacks SELECT permission on
V$DATABASE - Solution: Grant the permission:
GRANT SELECT ON V$DATABASE TO <username>; - Note: ReplicaDB will continue with standard queries (current behavior) if SCN capture fails
If you see error ORA-08181: Specified SCN too old
- Cause: SCN is outside the undo retention window
- Solution: Increase Oracle’s
UNDO_RETENTIONparameter:ALTER SYSTEM SET UNDO_RETENTION = 3600;(seconds) - Alternative: Run replication during lower activity periods to reduce undo pressure
Example with parallel jobs:
############################# ReplicadB Basics #############################
mode=complete
jobs=8
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@${ORAHOST}:${ORAPORT}:${ORASID}
source.user=${ORAUSER}
source.password=${ORAPASS}
source.table=LARGE_ORDERS
############################# Sink Options #############################
sink.connect=jdbc:postgresql://${PGHOST}:${PGPORT}/${PGDB}
sink.user=${PGUSER}
sink.password=${PGPASS}
sink.table=orders
This configuration will automatically use flashback query for the 8 parallel threads, preventing ORA-01555 errors that commonly occur with large table replications (>120GB or multi-hour transfers).
Log output example:
When flashback query is active, you’ll see in the logs:
INFO OracleManager - Captured Oracle SCN for consistent read: 1234567890
DEBUG OracleManager - Using flashback query with SCN 1234567890
4.3 PostgreSQL Connector
The PostgreSQL connector uses the SQL COPY command and its implementation in JDBC PostgreSQL COPY bulk data transfer what offers great performance.
The PostgreSQL JDBC driver has much better performance if the network is not included in the data transfer. Therefore, it is recommended that ReplicaDB be executed on the same machine where the PostgreSQL database resides.
In terms of monitoring and control, it is interesting to identify the connection to PostgreSQL setting the property ApplicationName.
Example
source.connect=jdbc:postgresql://host:port/db
source.user=pguser
source.password=pgpassword
source.table=schema.table_name
source.connect.parameter.ApplicationName=ReplicaDB
4.4 Denodo Connector
The Denodo connector only applies as a source, since being a data virtualization, it is normally only used as a source.
To connect to Denodo, you can review the documentation for more information: Access Through JDBC
In terms of monitoring and control, it is interesting to identify the connection to PostgreSQL setting the property userAgent.
Example
source.connect=jdbc:vdb://host:port/db
source.user=vdbuser
source.password=vdbpassword
source.table=schema.table_name
source.connect.parameter.userAgent=ReplicaDB
4.5 Amazon S3 Connector
Amazon Simple Storage Service (Amazon S3) provides secure, durable, highly-scalable object storage. For information about Amazon S3, see Amazon S3.
The s3 protocol is used in a URL that specifies the location of an Amazon S3 bucket and a prefix to use for writing files in the bucket.
S3 URI format:
s3://S3_endpoint[:port]/bucket_name/[bucket_subfolder]
Example:
sink.connect=s3://s3.eu-west-3.amazonaws.com/replicadb/images
Connecting to Amazon S3 requires AccessKey and SecretKey provided by your Amazon S3 account. These security keys are specified as additional parameters in the connection.
You can use the AWS S3 connector on any system compatible with their API, such as MinIO or other cloud providers such as Dreamhost, Wasabi, Dell EMC ECS Object Storage
4.5.1 Row Object Creation Type
There are two ways to create objects in Amazon S3 through the connector:
- Generate a single CSV file for all rows of a source table
- Generate a binary object for each row of the source table
The behavior is set through the sink.connect.parameter.row.isObject property where it can be true or false.
The purpose of this feature when sink.connect.parameter.row.isObject = true is to be able to extract or replicate LOBs (Large Objects) from sources to single objects in AWS S3. Where for each row of the table the content of the LOB field (BLOB, CLOB, JSON, XMLTYPE, any …) will be the payload of the object in AWS S3.
Similarly, when sink.connect.parameter.row.isObject = false ReplicaDB will generate a single CSV file for all rows in the source table and upload it to AWS S3 in memory streaming, without intermediate files.
4.5.1.1 One Object Per Row
To generate an object for each row of the source table, it is necessary to set the following properties:
# Each row is a different object in s3
sink.connect.parameter.row.isObject=true
sink.connect.parameter.row.keyColumn=[The name of the source table column used as an object key in AWS S3]
sink.connect.parameter.row.contentColumn=[the name of the source table column used as a payload object of the object in AWS S3]
Example:
############################# ReplicadB Basics #############################
mode=complete
jobs=4
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@host:port:sid
source.user=orauser
source.password=orapassword
source.table=product_image
source.columns=product_id || '.jpg' as key_column, image as content_column
############################# Sink Options #############################
sink.connect=s3://s3.eu-west-3.amazonaws.com/replicadb/images
sink.connect.parameter.accessKey=ASDFKLJHIOVNROIUNVSD
sink.connect.parameter.secretKey=naBMm7jVRyeE945m1jIIxMomoRM9rMCiEvVBtQe3
# Each row is a different object in s3
sink.connect.parameter.row.isObject=true
sink.connect.parameter.row.keyColumn=key_column
sink.connect.parameter.row.contentColumn=content_column
The following objects will be generated in AWS S3:
4.5.1.2 One CSV For All Rows
To generate a single CSV file for all rows of a source table, it is necessary to set the following properties:
# All rows are only one CSV object in s3
sink.connect.parameter.csv.keyFileName=[the full name of the target file or object key in AWS S3]
The CSV file generated is RFC 4180 compliant whenever you disable the default escape with --sink-disable-scape as argument or on the options-file:
sink.disable.escape=true
IMPORTANT: To support multi-threaded execution and since it is not possible to append content to an existing AWS S3 file, ReplicaDB will generate one file per job, renaming each file with the taskid.
Example:
############################# ReplicadB Basics #############################
mode=complete
jobs=4
############################# Source Options #############################
source.connect=jdbc:oracle:thin:@host:port:sid
source.user=orauser
source.password=orapassword
source.table=product_description
############################# Sink Options #############################
sink.connect=s3://s3.eu-west-3.amazonaws.com/replicadb/images
sink.connect.parameter.accessKey=ASDFKLJHIOVNROIUNVSD
sink.connect.parameter.secretKey=naBMm7jVRyeE945m1jIIxMomoRM9rMCiEvVBtQe3
# All rows are only one CSV object in s3
sink.connect.parameter.csv.keyFileName=product_description.csv
sink.disable.escape=true
The following objects will be generated in AWS S3:
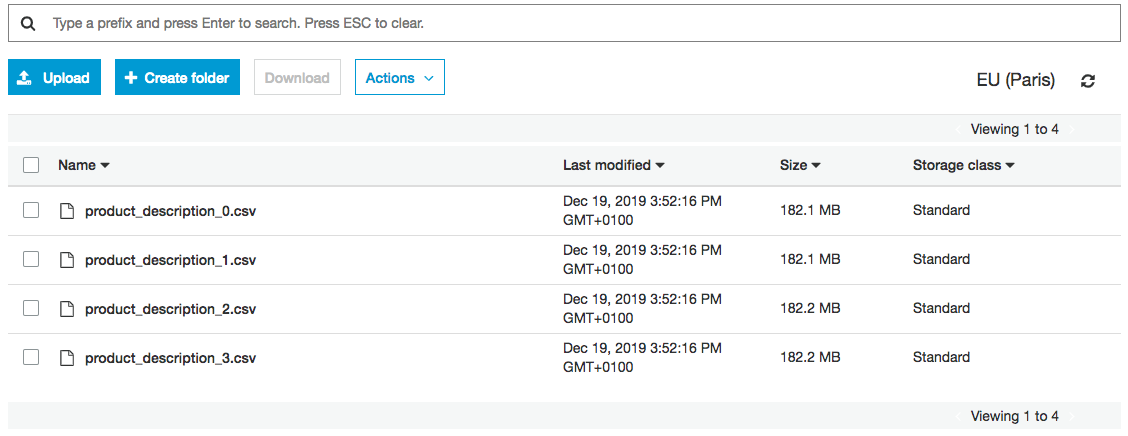
4.5.2 Extra parameters
The Amazon S3 connector supports the following extra parameters that can only be defined as extra connection parameters in the options-file:
| Parameter | Description | Default |
|---|---|---|
accessKey |
AWS S3 Access Key ID to access the S3 bucket | Required |
secretKey |
AWS S3 Secret Access Key for the S3 Access Key ID to access the S3 bucket | Required |
secure-connection |
Sets if the connection is secure using SSL (HTTPS) | true |
row.isObject |
Sets whether each row in the source table is a different object in AWS S3 | false |
row.keyColumn |
Sets the name of the column in the source table whose content will be used as objectKey (filename) in AWS S3 | Required when the row.isObject = true |
row.contentColumn |
Sets the name of the column in the source table whose content will be the payload of the object in AWS S3 | Required when the row.isObject = true |
csv.keyFileName |
Set the name of the target file or object key in AWS S3 | Required when the row.isObject = false |
csv.FieldSeparator |
Sets the field separator character | , |
csv.TextDelimiter |
Sets a field enclosing character | " |
csv.LineDelimiter |
Sets the end-of-line character | \n |
csv.AlwaysDelimitText |
Sets whether the text should always be delimited | false |
csv.Header |
Sets whether the first line of the file should be the header, with the names of the fields | false |
4.6 MySQL and MariaDB Connector
Because the MariaDB JDBC driver is compatible with MySQL, and the MariaDB driver has better performance compared to the MySQL JDBC driver, in ReplicaDB we use only the MariaDB driver for both databases.
This connector uses the SQL LOAD DATA INFILE command and its implementation in JDBC JDBC API Implementation Notes what offers great performance.
ReplicaDB automatically sets these connection properties that are necessary to use the LOAD DATA INFILE command:
characterEncoding=UTF-8allowLoadLocalInfile=truerewriteBatchedStatements=true
Example
source.connect=jdbc:mysql://host:port/db
source.user=pguser
source.password=pgpassword
source.table=schema.table_name
4.7 MSSQL Server Connector
ReplicaDB uses the MSSQL Server bulk copy API for load data into the database.
Oracle BLOB and CLOB columns are supported when replicating into SQL Server using bulk copy. Ensure sink columns use VARBINARY(MAX) for BLOB and NVARCHAR(MAX) for CLOB, and avoid casting these columns in the source query so they can be streamed during bulk copy.
Hence, depending on the source database, some data types are not supported by the MSSQL Server bulk copy, and must be cast during the replication process to avoid the Specification of length or precision 0 is invalid exception.
In addition, to avoid the exception Column xx is invalid. Please check your column mappings it will be necessary to include all source and sink columns.
In this example, 4 columns from table t_source in PostgresSQL are replicated to t_sink in MSSQL Server. The c_numeric and c_decimal columns are converted to text, the binary column is hex encoded and the xml type column is not supported by the bulk copy API, so it is converted to text.
Example
...
############################# Source Options ##############################
source.connect=jdbc:postgresql://localhost:5432/postgres
source.user=root
source.password=ReplicaDB_1234
source.table=public.t_source
source.columns=c_numeric::text,\
c_decimal::text,\
encode(c_binary_lob, 'hex'),\
c_xml::text
############################# Sink Options ################################
sink.connect=jdbc:sqlserver://localhost:1433;database=master
sink.user=sa
sink.password=ReplicaDB_1234
sink.table=dbo.t_sink
sink.staging.schema=dbo
sink.columns=c_numeric, c_decimal, c_binary_blob, c_xml
XML Column Performance
Important: When replicating XML data to SQL Server, it is recommended to use a smaller batch size to ensure optimal performance and reliability.
Recommended Configuration:
fetch.size=1
Why this matters:
SQL Server’s bulk copy API requires XML data to be properly formatted with an XML declaration. ReplicaDB automatically adds the declaration (<?xml version="1.0" encoding="UTF-8"?>) when missing. However, SQL Server 2019’s bulk copy parser has limitations when processing multiple XML rows in a single batch.
Important: This limitation is specific to SQL Server 2019 (tested with CU29). It has not been observed in Azure SQL Database/Azure SQL Edge, which handle XML bulk copy operations with larger batch sizes without issues.
Performance Characteristics:
- Batch size 1: Maximum reliability (recommended for SQLServer 2019→SQLServer 2019)
- Batch size 2: Good reliability (recommended for PostgreSQL/Oracle→SQLServer 2019)
- Batch size > 2: May experience intermittent parsing failures on SQL Server 2019
- Default (fetch.size=100): Not recommended for XML columns with SQL Server 2019 sink
Example Configuration for XML Replication:
######################## ReplicadB General Options ########################
mode=complete
jobs=1
fetch.size=1
############################# Source Options ##############################
source.connect=jdbc:postgresql://localhost:5432/postgres
source.user=root
source.password=ReplicaDB_1234
source.table=public.t_source
source.columns=c_integer, c_varchar, c_xml
############################# Sink Options ################################
sink.connect=jdbc:sqlserver://localhost:1433;database=master
sink.user=sa
sink.password=ReplicaDB_1234
sink.table=dbo.t_sink
sink.staging.schema=dbo
sink.columns=c_integer, c_varchar, c_xml
Azure SQL Database / Azure SQL Edge:
If you are using Azure SQL Database or Azure SQL Edge as the sink, you can use larger batch sizes (the default fetch.size=100 works well) as these platforms do not exhibit the same XML bulk copy limitations as SQL Server 2019.
Note: This limitation only applies when XML columns are present in the replicated data. For tables without XML columns, you can use the default batch size (100) for optimal performance on all SQL Server variants.
4.8 SQLite Connector
In the SQLite connector the complete-atomic mode is not supported because replicadb performs multiple transactions on the same table and rows and cannot control the transaction isolation level.
Example
...
######################## ReplicadB General Options ########################
mode=complete
jobs=1
############################# Source Options ##############################
source.connect=jdbc:postgresql://localhost:5432/postgres
source.user=sa
source.password=root
source.table=t_source
############################# Sink Options ################################
sink.connect=jdbc:sqlite:/tmp/replicadb-sqlite.db
sink.table=main.t_sink
sink.staging.schema=main
4.9 MongoDB Connector
The MongoDB connector in ReplicaDB allows you to replicate data between MongoDB databases and other databases supported by ReplicaDB. The MongoDB connector uses the MongoDB Bulk API to perform the replication.
Configuration To configure the MongoDB connector, you will need to specify the following options in your ReplicaDB configuration file.
Note that source.user, source.password, sink.user and sink.password are not compatible and must be defined in the URI connection string in the source.connect and sink.connect options.
The source.connect and sink.connect URI string follows the MongoDB URI format:
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]- For MongoDB Atlas:
mongodb+srv://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
The database name in the URI connection string is required.
Source Options
| Parameter | Description |
|---|---|
source.connect |
The MongoDB connection string with username and password. Compatible with MongoDB Atlas mongodb+srv |
source.user |
Not compatible |
source.password |
Not compatible |
source.table |
The name of the collection in the source database to replicate from |
source.columns |
The list of columns to replicate from the source collection ($projection). In JSON format |
source.where |
A query filter to apply to the source collection. in JSON format |
source.query |
An aggregation pipeline (aggregate) to execute on the source collection. In Array JSON format |
Sink Options
| Parameter | Description |
|---|---|
sink.connect |
The MongoDB connection string with username and password. Compatible with MongoDB Atlas mongodb+srv |
sink.user |
Not compatible |
sink.password |
Not compatible |
sink.table |
The name of the collection in the sink database to replicate to |
Incremental Replication
The MongoDB connector supports incremental replication using the source.query or source.where options. To enable incremental replication, you will need to specify a source.query aggregation pipeline that includes a $match stage to filter the documents to be replicated or a source.where query filter.
The incremental mode for MongoDB as sink database uses the $merge statement to update the documents in the sink collection. The $merge statement requires a unique index on some field in the sink collection. If the sink collection does not have a unique index, ReplicaDB will throw an exception.
Note that the $merge stage is supported since MongoDB 4.2 and later.
For example, to replicate all documents in the source_collection with a timestamp field greater than or equal to the current time, you could use the following configuration:
Using source.query
mode=incremental
source.query=[{$match: {timestamp: {$gte: new Date()}}},{$sort: {timestamp: 1}}]
source.table=source_collection
sink.table=sink_collection
Using source.where
mode=incremental
source.where={timestamp: {$gte: new Date()}}
source.table=source_collection
sink.table=sink_collection
Examples
1.Replicate all documents from a collection in local MongoDB instance to a collection in remote MongoDB Atlas instance:
######################## ReplicadB General Options ########################
mode=complete
jobs=1
fetch.size=100
############################# Source Options ##############################
source.connect=mongodb://root:password@127.0.0.1/catalog
source.table=products
############################# Sink Options ################################
sink.connect=mongodb+srv://user:password@cluster0.qwertyh.mongodb.net/catalog?retryWrites=true&w=majority
sink.table=products
2.Replicate a subset of documents from a collection in a local mongodb instance to a collection in a remote mongodb instance, using the source.query option to specify a mongodb aggregation pipeline:
######################## ReplicadB General Options ########################
mode=complete
jobs=1
fetch.size=100
############################# Source Options ##############################
source.connect=mongodb://root:password@127.0.0.1/catalog
source.table=products
source.query=[{ $match : {startDate:{$gte:ISODate("2021-01-01T00:00:00.000Z")}} } \
,{$sort:{startDate:1}} \
,{$project: {_id:0, shopId:1, productId:1, price:1, startDate:1} } ]
############################# Sink Options ################################
sink.connect=mongodb+srv://user:password@cluster0.qwertyh.mongodb.net/catalog?retryWrites=true&w=majority
sink.table=products
3.Replicate a table from a local Postgres database to a collection in a remote MongoDB Atlas instance:
######################## ReplicadB General Options ########################
mode=complete
jobs=1
fetch.size=100
verbose=true
############################# Source Options ##############################
source.connect=jdbc:postgresql://localhost:5432/postgres
source.user=user
source.password=password
source.table=t_roles
# Rename source columns to match mongodb collection sink fields
source.columns=id as "rolId", txt_code as code, txt_role_name as "roleName" \
, cod_v_usuario_creacion as "createdBy", fec_dt_creacion as "createdAt" \
, cod_v_usuario_modificacion as "updatedBy", fec_dt_modificacion as "updatedAt"
############################# Sink Options ################################
sink.connect=mongodb+srv://user:password@cluster0.qwertyh.mongodb.net/catalog?retryWrites=true&w=majority
sink.table=roles
4.Replicate a collection from a remote MongoDB Atlas instance to a local Postgres database.
It’s mandatory to specify the source.columns projection and sink.columns options to match the source collection fields to the sink table columns.
######################## ReplicaDB General Options ########################
mode=complete
jobs=1
fetch.size=100
verbose=true
############################# Source Options ##############################
source.connect=mongodb+srv://user:password@cluster0.qwertyh.mongodb.net/catalog
source.table=roles
source.columns={_id:0,rolId:1,roleName:1,createdBy:1,createdAt:1,updatedBy:1,updatedAt:1}
source.where={createdAt:{$gte:ISODate("2021-01-01T00:00:00.000Z")}}
############################# Sink Options ################################
sink.connect=jdbc:postgresql://localhost:5432/postgres
sink.user=user
sink.password=password
sink.table=t_roles
sink.columns=id, txt_role_name, cod_v_usuario_creacion, fec_dt_creacion, cod_v_usuario_modificacion, fec_dt_modificacion
5.Replicate a collection from a remote MongoDB Atlas instance to a local Postgres database using the Postgres jsonb data type and projection some fields from the source collection.
It’s mandatory to specify the source.columns projection and sink.columns options to match the source collection fields to the sink table columns.
######################## ReplicaDB General Options ########################
mode=complete
jobs=1
fetch.size=100
verbose=true
############################# Source Options ##############################
source.connect=mongodb+srv://user:password@cluster0.qwertyh.mongodb.net/catalog
source.table=products
source.columns={_id:0,sku:1, document:'$$ROOT'}
############################# Sink Options ################################
sink.connect=jdbc:postgresql://localhost:5432/postgres
sink.user=user
sink.password=password
sink.table=products_jsonb
sink.columns=sku, document
You can also replicate from Postgres jsonb to MongoDB using the jsonb data type. ReplicaDB will automatically convert the jsonb data type to a MongoDB document.
4.10 DB2 Connector
ReplicaDB supports IBM DB2 LUW and DB2 for i (AS/400) as source and sink databases.
JDBC URL formats
- DB2 LUW (IBM JCC driver):
jdbc:db2://<host>:<port>/<database> - DB2 for i (JTOpen driver):
jdbc:as400://<host>:<port>/<database>
Driver classes
- DB2 LUW:
com.ibm.db2.jcc.DB2Driver - DB2 for i:
com.ibm.as400.access.AS400JDBCDriver
Example (DB2 LUW)
source.connect=jdbc:db2://db2-host:50000/sample
source.user=db2user
source.password=db2pass
source.table=public.t_source
sink.connect=jdbc:db2://db2-host:50000/sample
sink.user=db2user
sink.password=db2pass
sink.table=public.t_sink
Example (DB2 for i)
source.connect=jdbc:as400://as400-host:446/sample
source.user=db2user
source.password=db2pass
source.table=QGPL.T_SOURCE
sink.connect=jdbc:as400://as400-host:446/sample
sink.user=db2user
sink.password=db2pass
sink.table=QGPL.T_SINK
5. Troubleshooting
This section covers common issues and their solutions when using ReplicaDB.
5.1 Connection Failures
Problem: Unable to connect to source or sink database
Common Causes:
- Incorrect JDBC URL format
- Network connectivity issues
- Firewall blocking database ports
- Database server not running
Solutions:
- Verify JDBC URL syntax matches database vendor requirements
- Test network connectivity:
telnet <host> <port>ornc -zv <host> <port> - Check firewall rules allow connections to database ports
- Confirm database service is running:
systemctl status <database-service> - Enable verbose logging:
--verboseor-v
Example Error:
ERROR SqlManager: Could not connect to database: Communications link failure
Fix: Verify hostname, port, and network connectivity.
5.2 Permission Errors
Problem: Access denied or insufficient privileges
Common Causes:
- Missing SELECT permissions on source tables
- Missing INSERT/UPDATE/DELETE permissions on sink tables
- Missing CREATE TABLE permissions for staging tables
Solutions:
- Source: Grant SELECT:
GRANT SELECT ON table TO user; - Sink: Grant necessary permissions:
GRANT INSERT, UPDATE, DELETE ON table TO user; GRANT CREATE TABLE ON schema TO user; - Verify permissions:
SHOW GRANTS FOR user;(MySQL) or\du(PostgreSQL)
Example Error:
ERROR OracleManager: ORA-01031: insufficient privileges
ERROR PostgresqlManager: permission denied for table
5.3 Memory Issues
Problem: Out of memory errors or slow performance
Common Causes:
- Insufficient Java heap size
- Large
--fetch-sizevalue - Too many parallel jobs for available memory
Solutions:
- Increase JVM memory: Set
JAVA_OPTS="-Xmx2g"before running ReplicaDB - Reduce fetch size:
--fetch-size=50(default is 100) - Reduce parallelism:
--jobs=2(default is 4) - Monitor memory usage during replication
Example Error:
java.lang.OutOfMemoryError: Java heap space
Fix: Set appropriate JVM memory based on available RAM:
export JAVA_OPTS="-Xmx4g" # 4GB heap
replicadb --options-file config.conf
5.4 Performance Problems
Problem: Replication is slower than expected
Common Causes:
- Suboptimal fetch size
- Too few or too many parallel jobs
- Network latency between databases
- Missing indexes on source tables
- No bandwidth throttling on constrained networks
Solutions:
- Optimize fetch size: The default of 100 works well for most scenarios. Increase to 200-500 only for narrow tables on high-latency networks. Reduce to 50 for wide tables or high parallelism.
- Adjust parallelism:
- Local databases:
--jobs=8to--jobs=16 - Remote databases:
--jobs=4to--jobs=8
- Local databases:
- Add indexes: Create indexes on columns used in
--source-whereclauses - Use bandwidth throttling:
--bandwidth-throttling=10240(10 MB/s) - Monitor database: Check CPU, I/O, and connection pool usage
Diagnostic commands:
# Run with verbose mode
replicadb --verbose --options-file config.conf
# Monitor with different job counts
replicadb --jobs=4 ... # Test baseline
replicadb --jobs=8 ... # Test with more parallelism
5.5 Log Configuration
Problem: Need more detailed logging for diagnosis
Solution: Configure Log4j2 logging level
Edit $REPLICADB_HOME/conf/log4j2.xml:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n"/>
</Console>
</Appenders>
<Loggers>
<!-- Set to DEBUG for detailed logging -->
<Root level="INFO">
<AppenderRef ref="Console"/>
</Root>
<!-- Enable specific package logging -->
<Logger name="org.replicadb" level="DEBUG"/>
</Loggers>
</Configuration>
Or use command-line option:
replicadb --verbose --options-file config.conf
Log Levels:
ERROR: Only critical errorsWARN: Warnings and errorsINFO: General information (default)DEBUG: Detailed diagnostic informationTRACE: Very detailed trace information
6. Performance Tuning
This section provides guidelines for optimizing ReplicaDB performance for large-scale data replication.
6.1 Optimal Parallelism
The --jobs parameter controls the number of parallel threads used for replication. Finding the right balance is crucial for performance.
General Guidelines:
- Default: 4 parallel jobs (suitable for most scenarios)
- Local databases: 8-16 jobs (when both databases are on same network/server)
- Remote databases: 4-8 jobs (balance network bandwidth and database load)
- Limited resources: 1-2 jobs (reduce memory and CPU pressure)
Considerations:
- Monitor database CPU and connection pool usage
- Each job opens one connection to source and sink
- More jobs = more memory consumption
- Network bandwidth may become bottleneck before CPU
Example:
# High-performance local replication
replicadb --jobs=12 --source-connect=... --sink-connect=...
# Conservative remote replication
replicadb --jobs=4 --source-connect=... --sink-connect=...
6.2 Fetch Size Optimization
The --fetch-size parameter controls how many rows are buffered in memory when reading from the source database. In ReplicaDB this same value is also used as the JDBC batch size for sink inserts, so it affects both read and write performance.
Default: 100 rows
Recommended range: 50–500
Why the Default is 100
The default of 100 is based on industry-wide JDBC benchmarking and database vendor guidance:
- Oracle JDBC defaults to only 10 rows per fetch, which is optimized for OLTP but terrible for bulk transfers. Increasing to 100 yields roughly 10× fewer network round-trips.
- PostgreSQL JDBC fetches the entire ResultSet into memory by default (when autocommit is on). With cursors enabled, their documentation examples use 50 as a reference value.
- Hibernate ORM recommends JDBC batch sizes “between 10 and 50” and uses 25 in its code examples.
- Practitioner consensus converges on 50–200 as the sweet spot for bulk data operations, with diminishing returns beyond 500.
At 100, ReplicaDB sits at the empirical sweet spot where network round-trips are reduced 10× compared to driver defaults, while memory consumption and GC pressure remain bounded.
Why Higher Values Can Hurt
Increasing fetch size beyond 500 often provides little benefit and can actively degrade performance:
- Oracle pre-allocates memory based on
max_possible_column_width × fetch_size, not actual data size. A table withVARCHAR2(4000)columns reserves 4000 bytes per column per row in the fetch buffer, even if actual values average 20 bytes. This makes large fetch sizes disproportionately expensive for wide tables. - GC pressure increases with larger buffers, causing periodic pauses that reduce throughput.
- Diminishing returns: benchmarks show ~10% improvement going from 10 to 100, but less than 2% improvement going from 100 to 1000.
- MySQL JDBC does not use fetch size in the traditional sense — it either streams row-by-row or fetches everything at once. The
useCursorFetch=truemode supports fetch size but is not the default behavior.
Understanding Memory Impact
Fetch size directly controls memory per job because the database driver must hold all fetched rows in memory. The total memory footprint is calculated as:
Total memory = fetch_size × average_row_size × number_of_jobs
Example: With --fetch-size=100, --jobs=4, and 1KB average row size:
- Memory per job: 100 × 1KB = 100 KB
- Total across all jobs: 100 KB × 4 = 400 KB (very low)
With --fetch-size=500 and the same parameters:
- Memory per job: 500 × 1KB = 500 KB
- Total across all jobs: 500 KB × 4 = 2 MB (still very reasonable)
Important: For Oracle, the actual memory used can be much higher than
row_count × average_data_sizebecause the driver allocates based on declared column widths, not actual data. A table with 10VARCHAR2(4000)columns at fetch size 500 could allocate up to 10 × 4000 × 500 = 20 MB per connection, regardless of actual data.
Guidelines by Scenario
| Scenario | Recommended Fetch Size | Rationale |
|---|---|---|
| Default / general use | 100 (default) |
Best balance for most workloads |
| Wide tables (many columns, large VARCHAR) | 50–100 |
Oracle/SQL Server pre-allocate based on max column widths |
| Narrow tables (few numeric/small text columns) | 200–500 |
Small rows allow buffering more with minimal memory |
| Memory constrained (<2GB heap) | 50 |
Reduce memory pressure, especially with multiple jobs |
| High parallelism (>8 jobs) | 50–100 |
Keep per-job memory low as total = fetch_size × jobs |
| High-latency network (cross-datacenter) | 200–500 |
Reduce round-trips to compensate for network latency |
How to Diagnose Fetch Size Problems
Symptom: Replication is slow with low CPU and network usage
- Cause: Fetch size too low, causing excessive network round-trips
- Fix: Increase
--fetch-sizeby 50% increments (e.g., 100 → 150 → 200)
Symptom: OutOfMemoryError or gradual slowdown over time
- Cause: Fetch size too high for available heap, especially with wide tables
- Fix: Reduce
--fetch-sizeto 50 and increase cautiously
Symptom: Performance degrades when increasing --jobs
- Cause: Total memory = fetch_size × jobs exceeds available heap
- Fix: Reduce
--fetch-sizeproportionally when adding jobs- Rule of thumb: if doubling jobs, halve fetch size to maintain same memory pressure
Examples
# Default: suitable for most workloads
replicadb --fetch-size=100 --jobs=4 ...
# Narrow rows, high-latency network: buffer more to reduce round-trips
replicadb --fetch-size=300 --jobs=4 ...
# Wide Oracle table (many VARCHAR2 columns): keep fetch size conservative
replicadb --fetch-size=50 --jobs=4 ...
# High parallelism: reduce fetch size to keep total memory bounded
replicadb --fetch-size=50 --jobs=12 ...
Important: When adjusting parallelism, recalculate fetch size:
# If increasing from 4 to 8 jobs, consider reducing fetch size
# Old: --fetch-size=200 --jobs=4 (total: 200×4 = 800 row buffers)
# New: --fetch-size=100 --jobs=8 (total: 100×8 = 800 row buffers) — same memory
Note: Values above 500 are generally not recommended. Benchmarks across Oracle, PostgreSQL, and Hibernate consistently show diminishing returns beyond this point, with increased risk of memory issues on wide tables.
6.3 Network Optimization
Bandwidth Throttling
Use --bandwidth-throttling to prevent network saturation when sharing bandwidth with other services.
Syntax: --bandwidth-throttling=<KB/s>
Examples:
# Limit to 10 MB/s total
replicadb --bandwidth-throttling=10240 ...
# No limit (default)
replicadb --bandwidth-throttling=0 ...
Important: Bandwidth limit is per job. With 4 jobs and 10 MB/s limit, actual usage could reach 40 MB/s.
Network Proximity
- Run ReplicaDB close to the database with slower network connection
- Prefer internal/private networks over public internet
- Use compression for WAN transfers (if supported by database)
6.4 Database-Specific Optimizations
Oracle
- Use direct path hints:
SELECT /*+ PARALLEL(4) */ ...via--source-query - Enable parallel DML on sink:
ALTER SESSION ENABLE PARALLEL DML - Consider partitioned tables for very large datasets
PostgreSQL
- Adjust
work_memfor better sort performance - Use
--source-whereto leverage partition pruning - Consider
UNLOGGEDtables for sink during initial load (then convert to logged)
MySQL/MariaDB
- Disable binary logging temporarily:
SET SQL_LOG_BIN=0(if acceptable) - Use bulk insert optimization: ensured by ReplicaDB automatically
- Consider
--sink-disable-escapeif data is pre-validated
MongoDB
- Use appropriate read concern:
readConcern=localfor performance - Create indexes after bulk load, not before
- Use projection (
--source-columns) to reduce data transfer
6.5 Performance Monitoring
Key Metrics to Monitor:
- Throughput: Rows per second
- Database CPU and I/O utilization
- Network bandwidth usage
- Memory consumption (Java heap)
- Connection pool saturation
Diagnostic Approach:
- Start with defaults (
--jobs=4,--fetch-size=100) - Run test replication and measure baseline
- Adjust one parameter at a time
- Monitor bottleneck (CPU, network, or I/O)
- Iterate until optimal performance
Example Baseline Test:
# Test 1: Baseline (default fetch size)
time replicadb --mode=complete --verbose ...
# Test 2: More parallelism
time replicadb --mode=complete --jobs=8 --verbose ...
# Test 3: Slightly larger fetch size (for narrow rows)
time replicadb --mode=complete --jobs=8 --fetch-size=200 --verbose ...
Expected Performance:
- Small tables (<1M rows): 50,000-100,000 rows/sec
- Medium tables (1M-10M rows): 20,000-50,000 rows/sec
- Large tables (>10M rows): 10,000-30,000 rows/sec
Actual performance varies based on hardware, network, database configuration, and row complexity.
7. Architecture
This section explains ReplicaDB’s internal architecture and design principles.
7.1 Overview
ReplicaDB uses a simple yet efficient architecture designed for high-performance bulk data transfer:
┌─────────────────────────────────────────────────────────────┐
│ ReplicaDB Process │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ ┌──────────────┐ ┌─────────┐ │
│ │ CLI Parser │─────▶│ Config Manager│─────▶│ Manager │ │
│ └───────────────┘ └──────────────┘ │ Factory │ │
│ └─────────┘ │
│ │ │
│ ┌───────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Source Manager │ Sink Manager │ │
│ │ (Oracle, Postgres, │ (Oracle, Postgres, │ │
│ │ MySQL, MongoDB, etc) │ MySQL, MongoDB, etc) │ │
│ └──────┬──────────────────┴──────────┬─────────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Parallel │ │ Parallel │ │
│ │ Reader Tasks │ │ Writer Tasks │ │
│ │ (1...N jobs) │───────────▶│ (1...N jobs) │ │
│ └──────────────┘ └──────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
│ │
▼ ▼
┌────────┐ ┌────────┐
│ Source │ │ Sink │
│Database│ │Database│
└────────┘ └────────┘
7.2 Core Components
Connection Layer
Purpose: Manages database connections using JDBC drivers or native protocols.
Key Features:
- JDBC connection pooling
- Native protocol support for MongoDB (MongoDB Java Driver)
- Kafka producer/consumer integration
- File system access for CSV and S3
Responsibilities:
- Establish and validate connections
- Handle authentication
- Manage connection lifecycle
Data Reader (Source Manager)
Purpose: Extracts data from the source database in parallel.
Key Features:
- Database-specific optimization (e.g., Oracle hash partitioning, PostgreSQL OFFSET)
- Configurable fetch size for memory management
- Support for custom queries via
--source-query - WHERE clause filtering via
--source-where
Parallel Processing:
- Splits work across N jobs (threads)
- Each job reads a partition of the data
- Uses database-specific partitioning strategies:
- Oracle:
ORA_HASH(ROWID, N) - PostgreSQL:
OFFSETandLIMIT - MySQL/MariaDB: Primary key ranges
- MongoDB: Collection splitting
- Oracle:
Data Writer (Sink Manager)
Purpose: Writes data to the sink database in parallel using optimized batch operations.
Key Features:
- Database-specific bulk operations (e.g., Oracle
APPEND_VALUES, PostgreSQLCOPY) - Automatic type mapping between different databases
- Staging table management for
incrementalandcomplete-atomicmodes - UPSERT operations for incremental replication
Batch Operations:
- Batches inserts for efficiency
- Uses native bulk load APIs when available
- Handles transaction management
Flow Control
Purpose: Coordinates the overall replication process and manages resources.
Key Features:
- Job scheduling and thread pool management
- Bandwidth throttling (per-job rate limiting)
- Progress monitoring and logging
- Error handling and retry logic
Process Flow:
- Parse command-line arguments and configuration
- Validate connections to source and sink
- Determine partitioning strategy based on database and table
- Launch N parallel jobs
- Each job reads from source and writes to sink
- Wait for all jobs to complete
- Perform post-processing (staging table merge, cleanup)
State Management
Purpose: Tracks replication progress and manages incremental updates.
Key Features:
- Staging table creation and management
- Primary key detection for UPSERT operations
- Transaction coordination for
complete-atomicmode - Metadata tracking (row counts, timing)
Replication Modes:
- Complete: Truncate + parallel insert
- Complete-Atomic: Staging table + atomic swap
- Incremental: Staging table + UPSERT merge
7.3 Data Flow
Complete Mode
1. Truncate sink table
2. [Job 1] Read partition 1 → Write to sink
3. [Job 2] Read partition 2 → Write to sink
4. [Job N] Read partition N → Write to sink
5. All jobs complete → Done
Complete-Atomic Mode
1. Create staging table
2. Start DELETE transaction (async)
3. [Job 1] Read partition 1 → Write to staging
4. [Job 2] Read partition 2 → Write to staging
5. [Job N] Read partition N → Write to staging
6. Wait for DELETE to complete
7. INSERT INTO sink SELECT FROM staging (atomic)
8. Commit transaction
9. Drop staging table
Incremental Mode
1. Create staging table
2. [Job 1] Read new data partition 1 → Write to staging
3. [Job 2] Read new data partition 2 → Write to staging
4. [Job N] Read new data partition N → Write to staging
5. UPSERT from staging to sink (using primary keys)
6. Drop staging table
7.4 Design Principles
Convention Over Configuration
ReplicaDB applies sensible defaults to minimize configuration:
- Automatic partitioning strategy selection
- Default fetch size (5000) and parallelism (4 jobs)
- Automatic type mapping between databases
- Intelligent staging table naming
Database-Agnostic Interface
Each database has a Manager class implementing a common interface:
read(): Extract datawrite(): Load datagetPartitioningStrategy(): Define how to split workgetSupportedModes(): Define capabilities
This allows adding new databases without changing core logic.
Performance-First Design
- Parallel processing by default
- Bulk operations over row-by-row
- Database-specific optimizations (Oracle hints, PostgreSQL COPY)
- Minimal memory footprint through streaming
Simplicity
- Single JAR with embedded dependencies
- No external daemons or agents
- No database triggers or schema modifications
- Command-line only (no GUI overhead)